Выбор читателей





Популярные статьи
Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г . Синтаксис этого выражения имеет следующий вид:
ДИСП.Г(Число1;Число2;…)
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.


В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
ДИСП.В(Число1;Число2;…)
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.


Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Вариационный размах (или размах вариации) - это разница между максимальным и минимальным значениями признака:
В нашем примере размах вариации сменной выработки рабочих составляет: в первой бригаде R=105-95=10 дет., во второй бригаде R=125-75=50 дет. (в 5 раз больше). Это говорит о том, что выработка 1-й бригады более «устойчива», но резервов роста выработки больше у второй бригады, т.к. в случае достижения всеми рабочими максимальной для этой бригады выработки, ею может быть изготовлено 3*125=375 деталей, а в 1-й бригаде только 105*3=315 деталей.
Если крайние значения признака не типичны для совокупности, то используют квартильный или децильный размахи. Квартильный размах RQ= Q3-Q1 охватывает 50% объема совокупности, децильный размах первый RD1 = D9-D1охватывает 80% данных, второй децильный размах RD2= D8-D2 – 60 %.
Недостатком показателя вариационного размаха является, но что его величина не отражает все колебания признака.
Простейшим обобщающим показателем, отражающим все колебания признака, является среднее линейное отклонение
, представляющее собой среднюю арифметическую абсолютных отклонений отдельных вариант от их средней величины:
,
для сгруппированных данных ![]() ,
,
где хi – значение признака в дискретном ряду или середина интервала в интервальном распределении.
В вышеприведенных формулах разности в числителе взяты по модулю, иначе, согласно свойству средней арифметической, числитель всегда будет равен нулю. Поэтому среднее линейное отклонение в статистической практике применяют редко, только в тех случаях, когда суммирование показателей без учета знака имеет экономический смысл. С его помощью, например, анализируется состав работающих, рентабельность производства, оборот внешней торговли.
Дисперсия признака
– это средний квадрат отклонений вариант от их средней величины:
простая дисперсия![]() ,
,
взвешенная дисперсия .
.
Формулу для расчета дисперсии можно упростить:
Таким образом, дисперсия равна разности средней из квадратов вариант и квадрата средней из вариант совокупности: .
.
Однако, вследствие суммирования квадратов отклонений дисперсия дает искаженное представление об отклонениях, поэтому ее на основе рассчитывают среднее квадратическое отклонение
, которое показывает, на сколько в среднем отклоняются конкретные варианты признака от их среднего значения. Вычисляется путем извлечения квадратного корня из дисперсии:
для несгруппированных данных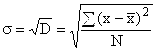 ,
,
для вариационного ряда
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность, тем более надежной (типичной) будет средняя величина.
Среднее линейное и среднее квадратичное отклонение - именованные числа, т. е. выражаются в единицах измерения признака, идентичны по содержанию и близки по значению.
Рассчитывать абсолютные показатели вариации рекомендуется с помощью таблиц.
Таблица 3 – Расчет характеристик вариации (на примере срока данных о сменной выработке рабочих бригады)
Число рабочих, |
Середина интервала, |
Расчетные значения |
|||||
Итого: |
|||||||
Среднесменная выработка рабочих:![]()
Среднее линейное отклонение:![]()
Дисперсия выработки: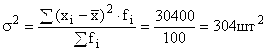
Среднее квадратическое отклонение выработки отдельных рабочих от средней выработки:
.
Вычисление дисперсий связано с громоздкими расчетами (особенно если средняя величина выражена большим числом с несколькими десятичными знаками). Расчеты можно упростить, если использовать упрощенную формулу и свойства дисперсии.
Дисперсия обладает следующими свойствами:
 ,
,
 , то или
, то или 
Используя свойства дисперсии и сначала уменьшив все варианты совокупности на величину А, а затем разделив на величину интервала h, получим формулу вычисления дисперсии в вариационных рядах с равными интервалами способом моментов:
 ,
,
где – дисперсия, исчисленная по способу моментов;
h – величина интервала вариационного ряда;
– новые (преобразованные) значения вариант;
А– постоянная величина, в качестве которой используют середину интервала, обладающего наибольшей частотой; либо вариант, имеющий наибольшую частоту;  – квадрат момента первого порядка;
– квадрат момента первого порядка;
– момент второго порядка.
Выполним расчет дисперсии способом моментов на основе данных о сменной выработке рабочих бригады.
Таблица 4 – Расчет дисперсии по способу моментов
Группы рабочих по выработке, шт. |
Число рабочих, |
Середина интервала, |
Расчетные значения |
||
Порядок расчета:


Среди признаков, изучаемых статистикой, есть и такие, которым свойственны лишь два взаимно исключающих значения. Это альтернативные признаки. Им придается соответственно два количественных значения: варианты 1 и 0. Частостью варианты 1, которая обозначается p, является доля единиц, обладающих данным признаком. Разность 1-р=q является частостью варианты 0. Таким образом,
хi |
|
Средняя арифметическая альтернативного признака![]() , т. к. p+q=1.
, т. к. p+q=1.
Дисперсия альтернативного признака
, т.к. 1-р=q
Таким образом, дисперсия альтернативного признака равна произведению доли единиц, обладающих данным признаком, и доли единиц, не обладающих этим признаком.
Если значения 1 и 0 встречаются одинаково часто, т. е. p=q, дисперсия достигает своего максимума pq=0,25.
Дисперсия альтернативного признака используется в выборочных обследованиях, например, качества продукции.
Дисперсия, в отличие от других характеристик вариации, является аддитивной величиной. То есть в совокупности, которая разделена на группы по факторному признаку х, дисперсия результативного признака y может быть разложена на дисперсию в каждой группе (внутригрупповую) и дисперсию между группами (межгрупповую). Тогда, наряду с изучением вариации признака по всей совокупности в целом, становится возможным изучение вариации в каждой группе, а также между этими группами.
Общая дисперсия
измеряет вариацию признака у
по всей совокупности под влиянием всех факторов, вызвавших эту вариацию (отклонения). Она равна среднему квадрату отклонений отдельных значений признака у
от общей средней и может быть вычислена как простая или взвешенная дисперсия.
Межгрупповая дисперсия
характеризует вариацию результативного признака у
, вызванную влиянием признака-фактора х
, положенного в основу группировки. Она характеризует вариацию групповых средних и равна среднему квадрату отклонений групповых средних от общей средней : ,
,
где – средняя арифметическая i-той группы;
– численность единиц в i-той группе (частота i-той группы);
– общая средняя совокупности.
Внутригрупповая дисперсия
отражает случайную вариацию, т. е. ту часть вариации, которая вызвана влиянием неучтенных факторов и не зависит от признака-фактора, положенного в основу группировки. Она характеризует вариацию индивидуальных значений относительно групповых средних, равна среднему квадрату отклонений отдельных значений признака у
внутри группы от средней арифметической этой группы (групповой средней) и вычисляется как простая или взвешенная дисперсия для каждой группы: ![]() или
или ![]() ,
,
где – число единиц в группе.
На основании внутригрупповых дисперсий по каждой группе можно определить общую среднюю из внутригрупповых дисперсий
:
.
Взаимосвязь между тремя дисперсиями получила название правила сложения дисперсий
, согласно которому общая дисперсия равна сумме межгрупповой дисперсии и средней из внутригрупповых дисперсий:
Пример
. При изучении влияния тарифного разряда (квалификации) рабочих на уровень производительности их труда получены следующие данные.
Таблица 5 – Распределение рабочих по среднечасовой выработке.
№ п/п |
Рабочие 4-го разряда |
Рабочие 5-го разряда |
|||||
Выработка |
Выработка |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
В данном примере рабочие разделены на две группы по факторному признаку х
– квалификации, которая характеризуется их разрядом. Результативный признак – выработка – варьируется как под его влиянием (межгрупповая вариация), так и за счет других случайных факторов (внутригрупповая вариация). Задача заключается в измерении этих вариаций с помощью трех дисперсий: общей, межгрупповой и внутригрупповой.
Эмпирический коэффициент детерминации показывает долю вариации результативного признака у
под влиянием факторного признака х
. Остальная часть общей вариации у
вызвана изменением прочих факторов.
В примере эмпирический коэффициент детерминации равен:![]() или 66,7 %,
или 66,7 %,
Это означает, что на 66,7% вариация производительности труда рабочих обусловлена различиями в квалификации, а на 33,3% – влиянием прочих факторов.
Эмпирическое корреляционное отношение
показывает тесноту связи между группировочным и результативными признаками. Рассчитывается как корень квадратный из эмпирического коэффициента детерминации:
Эмпирическое корреляционное отношение , как и , может принимать значения от 0 до 1.
Если связь отсутствует, то =0. В этом случае =0, то есть групповые средние равны между собой и межгрупповой вариации нет. Значит группировочный признак – фактор не влияет на образование общей вариации.
Если связь функциональная, то =1. В этом случае дисперсия групповых средних равна общей дисперсии (), то есть внутригрупповой вариации нет. Это означает, что группировочный признак полностью определяет вариацию изучаемого результативного признака.
Чем ближе значение корреляционного отношения к единице, тем теснее, ближе к функциональной зависимости связь между признаками.
Для качественной оценки тесноты связи между признаками пользуются соотношениями Чэддока.
В примере ![]() , что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
, что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
Запишите значения выборки. В большинстве случаев статистикам доступны только выборки определенных генеральных совокупностей. Например, как правило, статистики не анализируют расходы на содержание совокупности всех автомобилей в России – они анализируют случайную выборку из нескольких тысяч автомобилей. Такая выборка поможет определить средние расходы на автомобиль, но, скорее всего, полученное значение будет далеко от реального.
Запишите формулу для вычисления дисперсии выборки. Дисперсия является мерой разброса значений некоторой величины. Чем ближе значение дисперсии к нулю, тем ближе значения сгруппированы друг к другу. Работая с выборкой значений, используйте следующую формулу для вычисления дисперсии:
Вычислите среднее значение выборки. Оно обозначается как x̅. Среднее значение выборки вычисляется как обычное среднее арифметическое: сложите все значения в выборке, а затем полученный результат разделите на количество значений в выборке.
Вычтите выборочное среднее из каждого значения в выборке. Теперь вычислите разность x i {\displaystyle x_{i}} - x̅, где x i {\displaystyle x_{i}} – каждое значение в выборке. Каждый полученный результат свидетельствует о мере отклонения конкретного значения от выборочного среднего, то есть как далеко это значение находится от среднего значения выборки.
Как отмечалось выше, сумма разностей x i {\displaystyle x_{i}} - x̅ должна быть равна нулю. Это означает, что средняя дисперсия всегда равна нулю, что не дает никакого представления о разбросе значений некоторой величины. Для решения этой проблемы возведите в квадрат каждую разность x i {\displaystyle x_{i}} - x̅. Это приведет к тому, что вы получите только положительные числа, которые при сложении никогда не дадут 0.
Вычислите сумму квадратов разностей. То есть найдите ту часть формулы, которая записывается так: ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ]. Здесь знак Σ означает сумму квадратов разностей для каждого значения x i {\displaystyle x_{i}} в выборке. Вы уже нашли квадраты разностей (x i {\displaystyle (x_{i}} - x̅) 2 {\displaystyle ^{2}} для каждого значения x i {\displaystyle x_{i}} в выборке; теперь просто сложите эти квадраты.
Полученный результат разделите на n - 1, где n – количество значений в выборке. Некоторое время назад для вычисления дисперсии выборки статистики делили результат просто на n; в этом случае вы получите среднее значение квадрата дисперсии, которое идеально подходит для описания дисперсии данной выборки. Но помните, что любая выборка – это лишь небольшая часть генеральной совокупности значений. Если взять другую выборку и выполнить такие же вычисления, вы получите другой результат. Как выяснилось, деление на n - 1 (а не просто на n) дает более точную оценку дисперсии генеральной совокупности, в чем вы и заинтересованы. Деление на n – 1 стало общепринятым, поэтому оно включено в формулу для вычисления дисперсии выборки.
Отличие дисперсии от стандартного отклонения. Заметьте, что в формуле присутствует показатель степени, поэтому дисперсия измеряется в квадратных единицах измерения анализируемой величины. Иногда такой величиной довольно сложно оперировать; в таких случаях пользуются стандартным отклонением, которое равно квадратному корню из дисперсии. Именно поэтому дисперсия выборки обозначается как s 2 {\displaystyle s^{2}} , а стандартное отклонение выборки – как s {\displaystyle s} .
Проанализируйте некоторую совокупность значений. Совокупность включает в себя все значения рассматриваемой величины. Например, если вы изучаете возраст жителей Ленинградской области, то совокупность включает возраст всех жителей этой области. В случае работы с совокупностью рекомендуется создать таблицу и внести в нее значения совокупности. Рассмотрим следующий пример:
Запишите формулу для вычисления дисперсии генеральной совокупности. Так как в совокупность входят все значения некоторой величины, то приведенная ниже формула позволяет получить точное значение дисперсии совокупности. Для того чтобы отличить дисперсию совокупности от дисперсии выборки (значение которой является лишь оценочным), статистики используют различные переменные:
Вычислите среднее значение совокупности. При работе с генеральной совокупностью ее среднее значение обозначается как μ (мю). Среднее значение совокупности вычисляется как обычное среднее арифметическое: сложите все значения в генеральной совокупности, а затем полученный результат разделите на количество значений в генеральной совокупности.
Вычтите среднее значение совокупности из каждого значения в генеральной совокупности. Чем ближе значение разности к нулю, тем ближе конкретное значение к среднему значению совокупности. Найдите разность между каждым значением в совокупности и ее средним значением, и вы получите первое представление о распределении значений.
Возведите в квадрат каждый полученный результат. Значения разностей будут как положительными, так и отрицательными; если нанести эти значения на числовую прямую, то они будут лежать справа и слева от среднего значения совокупности. Это не годится для вычисления дисперсии, так как положительные и отрицательные числа компенсируют друг друга. Поэтому возведите в квадрат каждую разность, чтобы получить исключительно положительные числа.
Дисперсия случайной величины - мера разброса данной случайной величины , то есть её отклонения от математического ожидания. В статистике для обозначения дисперсии часто употребляется обозначение (сигма в квадрате). Квадратный корень из дисперсии , равный , называется стандартным отклонением или стандартным разбросом. Стандартное отклонение измеряется в тех же единицах, что и сама случайная величина, а дисперсия измеряется в квадратах этой единицы измерения.
Хотя для оценки всей выборки очень удобно использовать лишь одно значение (такое как среднее значение или моду и медиану), этот подход легко может привести к неправильным выводам. Причина такого положения лежит не в самой величине, а в том, что одна величина никак не отражает разброс значений данных.
Например, в выборке:
среднее значение равно 5.
Однако, в самой выборке нет ни одного элемента со значением 5. Возможно, Вам потребуется знать степень близости каждого элемента выборки к ее среднему значению. Или, другими словами, вам потребуется знать дисперсию значений. Зная степень изменения данных, Вы можете лучше интерпретировать среднее значение , медиану и моду . Степень изменения значений выборки определяется путем вычисления их дисперсии и стандартного отклонения.
Дисперсия и квадратный корень из дисперсии, называемый стандартным отклонением, характеризуют среднее отклонение от среднего значения выборки. Среди этих двух величин наибольшее значение имеет стандартное отклонение . Это значение можно представить как среднее расстояние, на котором находятся элементы от среднего элемента выборки.
Дисперсию трудно интерпретировать содержательно. Однако, квадратный корень из этого значения является стандартным отклонением и хорошо поддается интерпретации.
Стандартное отклонение вычисляется путем определения сначала дисперсии и затем вычисления квадратного корня из дисперсии.
Например, для массива данных, приведенных на рисунке, будут получены следующие значения:

Рисунок 1
Здесь среднее значение квадратов разностей равно 717,43. Для получения стандартного отклонения осталось лишь взять квадратный корень из этого числа.
Результат составит приблизительно 26,78.
Следует помнить, что стандартное отклонение интерпретируется как среднее расстояние, на котором находятся элементы от среднего значения выборки.
Стандартное отклонение показывает, насколько хорошо среднее значение описывает всю выборку.
Допустим, Вы являетесь руководителем производственного отдела по сборке ПК. В квартальном отчете говорится, что выпуск за последний квартал составил 2500 ПК. Плохо это или хорошо? Вы попросили (или уже в отчете есть эта графа) в отчете отобразить стандартное отклонение по этим данным. Цифра стандартного отклонения, например, равна 2000. Становится понятным для Вас, как руководителя отдела, что производственная линия требует лучшего управления (слишком большие отклонения по количеству собираемых ПК).
Вспомним: при большой величине стандартного отклонения данные широко разбросаны относительно среднего значения, а при маленькой – они группируются близко к среднему значению.
Четыре статистические функции ДИСП(), ДИСПР(), СТАНДОТКЛОН() и СТАНДОТКЛОНП() – предназначены для вычисления дисперсии и стандартного отклонения чисел в интервале ячеек. Перед тем как вычислять дисперсию и стандартное отклонение набора данных, нужно определить, представляют ли эти данные генеральную совокупность или выборку из генеральной совокупности. В случае выборки из генеральной совокупности следует использовать функции ДИСП() и СТАНДОТКЛОН(), а в случае генеральной совокупности – функции ДИСПР() и СТАНДОТЛОНП():
| Генеральная совокупность | Функция |
 | ДИСПР() |
 | СТАНДОТЛОНП() |
| Выборка | |
 | ДИСП() |
 | СТАНДОТКЛОН() |
Дисперсия (а так же стандартное отклонение), как мы отмечали, свидетельствуют о том, в какой степени входящие в набор данных величины разбросаны вокруг среднего арифметического.
Малое значение дисперсии или стандартного отклонения говорит о том, что все данные сосредоточены вокруг среднего арифметического, а большое значение этих величин – о том, что данные разбросаны в широком диапазоне значений.
Дисперсию достаточно трудно интерпретировать содержательно (что значит малое значение, большое значение?). Выполнение Задания 3 позволит визуально, на графике, показать смысл дисперсии для набора данных.
Задания
· Задание 1.
· 2.1. Дать понятия: дисперсия и стандартное отклонение; их символьное обозначение при статистической обработке данных.
· 2.2. Оформить рабочий лист в соответствии с рисунком 1 и произвести необходимые расчеты.
· 2.3. Привести основные формулы, используемые при расчетах
· 2.4. Пояснить все обозначения ( , , )
· 2.5. Пояснить практическое значение понятия дисперсия и стандартное отклонение.
Задание 2.
1.1. Дать понятия: генеральная совокупность и выборка; математическое ожидание и среднее арифметическое их символьное обозначение при статистической обработке данных.
1.2. В соответствии с рисунком 2 оформить рабочий лист и произвести расчеты.
1.3. Привести основные формулы, используемые при расчетах (для генеральной совокупности и выборке).

Рисунок 2
1.4. Объяснить, почему возможны получения таких значений средних арифметических в выборках как 46,43 и 48,78 (см. файл Приложение). Сделать выводы.
Задание 3.
Имеется две выборки с различным набором данных, но среднее для них будет одинаковым:

Рисунок 3
3.1. Оформить рабочий лист в соответствии с рисунком 3 и произвести необходимые расчеты.
3.2. Приведите основные формулы расчета.
3.3. Постройте графики в соответствии с рисунками 4, 5.
3.4. Поясните полученные зависимости.
3.5. Аналогичные вычисления проведите для данных двух выборок.
Исходная выборка 11119999
Значения второй выборки подбираете так, что бы среднее арифметическое для второй выборки было таким же, например,:

Подберите значения для второй выборки самостоятельно. Оформите вычисления и построения графиков подобно рисункам 3, 4, 5. Покажите основные формулы, которые использовали при вычислениях.
Сделайте соответствующие выводы.
Все задания оформить в виде отчета со всеми необходимыми рисунками, графиками, формулами и краткими пояснениями.
Примечание: построение графиков обязательно пояснить с рисунками и краткими пояснениями.
Вычислим в MS EXCEL дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим дисперсию , затем стандартное отклонение .
Дисперсия выборки (выборочная дисперсия, sample variance ) характеризует разброс значений в массиве относительно .
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
дисперсии выборки используется функция ДИСП() , англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог ДИСП.В() , англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция ДИСП.Г(), англ. название VARP, т.е. Population VARiance, которая вычисляет дисперсию для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у ДИСП.В() , у ДИСП.Г() в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция ДИСПР() .
Дисперсию выборки
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению . Обычно, чем больше величина дисперсии , тем больше разброс значений в массиве.
Дисперсия выборки является точечной оценкой дисперсии распределения случайной величины, из которой была сделана выборка . О построении доверительных интервалов при оценке дисперсии можно прочитать в статье .
Чтобы вычислить дисперсию случайной величины, необходимо знать ее .
Для дисперсии случайной величины Х часто используют обозначение Var(Х). Дисперсия равна квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X)) 2 ]
дисперсия вычисляется по формуле:

где x i – значение, которое может принимать случайная величина, а μ – среднее значение (), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет , то дисперсия вычисляется по формуле:

Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Некоторые свойства дисперсии :
Var(Х+a)=Var(Х), где Х - случайная величина, а - константа.
Var(aХ)=a 2 Var(X)
Var(Х)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)-2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Это свойство дисперсии используется в статье про линейную регрессию .
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y - случайные величины, Cov(Х;Y) - ковариация этих случайных величин.
Если случайные величины независимы (independent), то их ковариация равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе .
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1) 2 Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения .
Стандартное отклонение выборки - это мера того, насколько широко разбросаны значения в выборке относительно их .
По определению, стандартное отклонение равно квадратному корню из дисперсии :

Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется Коэффициент вариации (Coefficient of Variation, CV) - отношение Стандартного отклонения к среднему арифметическому , выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция =СТАНДОТКЛОН() , англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог =СТАНДОТКЛОН.В() , англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция СТАНДОТКЛОН.Г() , англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет стандартное отклонение для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1))
=КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Функция КВАДРОТКЛ() вычисляет сумму квадратов отклонений значений от их среднего . Эта функция вернет тот же результат, что и формула =ДИСП.Г(Выборка )*СЧЁТ(Выборка ) , где Выборка - ссылка на диапазон, содержащий массив значений выборки (). Вычисления в функции КВАДРОТКЛ() производятся по формуле:

Функция СРОТКЛ() является также мерой разброса множества данных. Функция СРОТКЛ() вычисляет среднее абсолютных значений отклонений значений от среднего . Эта функция вернет тот же результат, что и формула =СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка) , где Выборка - ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции СРОТКЛ () производятся по формуле:

| Статьи по теме: | |
|
Душевнобольное искусство
О том, что психическими расстройствами страдали Ван Гог и Камилла... Расторопша — лечебные свойства уникальной травы и продуктов из нее Расторопша семена полезные свойства и противопоказания
Довольно высокое растение, которое имеет крупные пурпурные или лиловые... Сценарий на юбилей любимой маме Угадай мелодию их кинофильмов
За плечами долгий брак,Он не шутка, не пустяк!Шестьдесят он длится лет,В... | |